Terminology
A few definitions before we dive into the main architecture documentation. Also note, Arch borrows from Envoy’s terminology to keep things consistent in logs and traces, and introduces and clarifies concepts are is relates to LLM applications.
Agent: An application that uses LLMs to handle wide-ranging tasks from users via prompts. This could be as simple as retrieving or summarizing data from an API, or being able to trigger complex actions like adjusting ad campaigns, or changing travel plans via prompts.
Arch Config: Arch operates based on a configuration that controls the behavior of a single instance of the Arch gateway. This where you enable capabilities like LLM routing, fast function calling (via prompt_targets), applying guardrails, and enabling critical features like metrics and tracing. For the full configuration reference of arch_config.yaml see here.
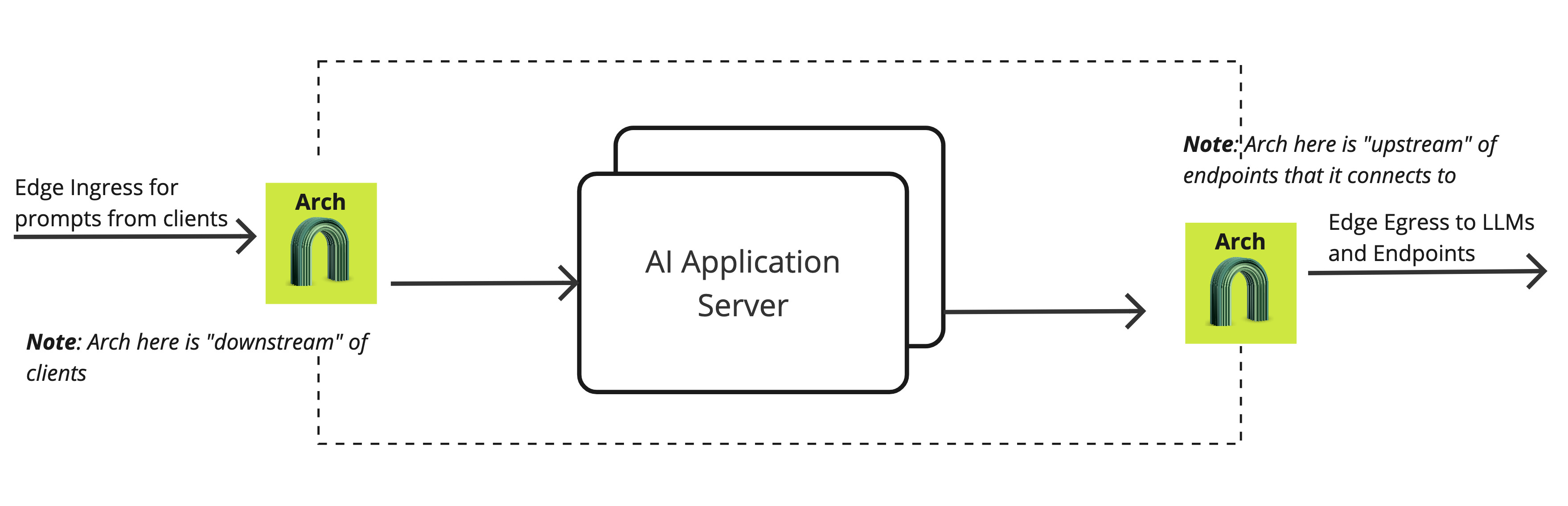
Downstream(Ingress): An downstream client (web application, etc.) connects to Arch, sends prompts, and receives responses.
Upstream(Egress): An upstream host that receives connections and prompts from Arch, and returns context or responses for a prompt
Listener: A listener is a named network location (e.g., port, address, path etc.) that Arch listens on to process prompts before forwarding them to your application server endpoints. rch enables you to configure one listener for downstream connections (like port 80, 443) and creates a separate internal listener for calls that initiate from your application code to LLMs.
Note
When you start Arch, you specify a listener address/port that you want to bind downstream. But, Arch uses are predefined port
that you can use (127.0.0.1:12000) to proxy egress calls originating from your application to LLMs (API-based or hosted).
For more details, check out LLM providers.
Prompt Target: Arch offers a primitive called prompt target to help separate business logic from undifferentiated work in building generative AI apps. Prompt targets are endpoints that receive prompts that are processed by Arch. For example, Arch enriches incoming prompts with metadata like knowing when a request is a follow-up or clarifying prompt so that you can build faster, more accurate retrieval (RAG) apps. To support agentic apps, like scheduling travel plans or sharing comments on a document - via prompts, Arch uses its function calling abilities to extract critical information from the incoming prompt (or a set of prompts) needed by a downstream backend API or function call before calling it directly.
Model Serving: Arch is a set of two self-contained processes that are designed to run alongside your application servers (or on a separate host connected via a network).The model serving process helps Arch make intelligent decisions about the incoming prompts. The model server is designed to call the (fast) purpose-built LLMs in Arch.
Error Target: Error targets are those endpoints that receive forwarded errors from Arch when issues arise,
such as failing to properly call a function/API, detecting violations of guardrails, or encountering other processing errors.
These errors are communicated to the application via headers X-Arch-[ERROR-TYPE], allowing it to handle the errors gracefully
and take appropriate actions.